Introduction
With massive growth of IoT, cloud industry rushes to provide scalable, reliable, resilient and secure ways to process and store enormous data coming from various devices around the world.Old self hosted data-centers within companies are deprecated and obsolete as they lack in scaling, difficult to maintain and can get quickly expensive. In short, these kind of platforms are overwhelmed by sudden rise of data.
With Modern problems, comes modern solutions; as you may already have guessed, it's AWS Web Services.
Getting powers from AWS cloud
What is AWS?
Amazon became a pioneer in cloud services technology (more than 195 services : https://aws.amazon.com/?nc1=h_ls). The most particularly common ones used in the wild are :- EC2 : Cloud computing service (IaaS), AWS offers also "load balancers" and "autoscaling groups" to handle any kind of traffic.
- S3 : Storage cloud service (can hold even files with size up to 5TB).
- RDS and DynamoDB : SQL (6 different database technologies are supported : MySQL, MariaDB, PostgreSQL, Oracle, MS SQL Server and Amazon Aurora) and NoSQL databases respectively.
- SQS : Queue service used to hold data until consumed.
- SNS : Notification service that acts as a message broker (dispatches messages from publishers to subscribers).
Interact with AWS services
AWS services can be accessed in 4 different ways :- Web console interface : one can use a web browser to navigate through various services and access most settings (the one used in this article).
- CLI interface : suitable for daily tasks. Ideal for administrators.
- Amazon SDK : AWS provides multiple SDK's for various programming languages (Python, Java, NodeJS, PHP and Android) to interact with AWS resources (subject to permissions).
- HTTP(s) requests : get and put requests are allowed to retrieve information and resources status.
Need for AWS
As embedded systems engineers; We need to collect, store and process enormous amount of data gathered from different smart devices powered by various technologies. A classical approach would as shown below :
- Enable NAT port forwarding on the company's router to allow external entities (Smart watches, Google glasses, Raspberry pi, Arduino, ..., etc) to reach your "Backend Server" (which runs a server side language like PHP or NodeJS) through provided REST APIs.
- Choose the database technology for your storage server : Relational (MySQL, PostgreSQL, ORACLE, ...,etc) or NoSQL (InfluxDB, Cassandra, MongoDB, ..., etc.) depending on your needs.
- Write some code on the backend (in addition to the code that provides the APIs) to read and process the data stored in the "Storage Server" whenever the front-end (browser) asks for it.
The above configuration will work fine but won't last for long.
solved :
- Database Scaling : imagine receiving millions of data per day, how can we make them fit into the above configuration? and how to replicate them?.
- System's redundancy : difficult to ensure 99.999999% reachable network (maintenance is usually required, remember the message : "We Will be back soon" on your favorite websites. Classical network are quickly flooded by huge amount of traffic.
- Security : Data in transit and data at rest must be protected. Yet, most companies fail to achieve this requirement.
- Not cost effective : need to pay for power consumption, cooling and maintenance.
Using a cloud solution like AWS, the above issues become a piece of cake to solve.
Let's introduce AWS to the above schematic which yields :

- Storage system : AWS databases (like dynamoDB) are scalable, one can store limitless amount of data. AWS replicates automatically your data over various availability zones and sometimes even over different regions.
- System's redundancy : AWS services are guaranteed to be accessible more than 99.999999% of time.
- Security : AWS is very known for it's security, one can tune access controls for every device and user. Some AWS services are even PCI compliant like SQS (Certified to transmit sensitive data like credit card information).
- Cost effective : as it provides a pay as you go (it may even be completely free if your have very low traffic).
With more than 190 services in AWS, We can implement a solution in different ways based on performance, latency and costs.
SNS and SQS AWS services
Let's make this as a getting started and discover two widely used AWS services : SQS and SNS. Most of the time, they are combined together to build Loosely coupled applications.- SNS (Simple Notification Service) :
also called push service (follows Publish-Subscribe model). Publisher can send messages and notifications to an SNS topic which dispatches them to every subscriber.
Important : Notification's size must not exceed 256 KB in SNS. - SQS :
also called a pull service. It allows to store messages (for a maximum of period of 14 days) in scalable queues. Your application can consume asynchronously the data stored in those queues (messages will be deleted at the moment your app confirms that it has successfully processed it).
For a developer, SQS means :
- Your network won't be hit by sudden spike requests as they are collected by Amazon.
- You have plenty of time to setup storage space on your network (in case you don't want to store those data in Amazon's services like DynamoDB).
The above two services are usually combined together to form a special configuration called "fan out".
Simple problem example
As a working example, let's say that your company sells "Geolocation Tags" for different customers. You need to process the data coming from all these Tags (storage, security, data statistics, ..., etc). Without a robust cloud setup, your network will not survive.As we have already stated, SQS and SNS are commonly used to build loosely coupled apps. Generally, they are combined to form the famous "fan out" configuration as shown below :
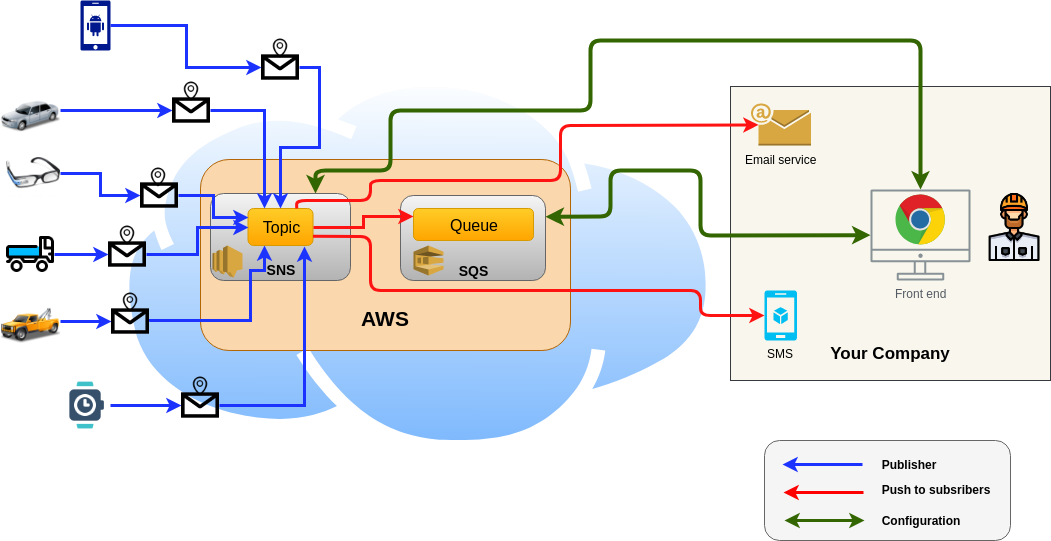
- All devices publish data to a single SNS topic.
- SNS relays all received data to all topic's subscribers (including SQS, an email account or even sending SMS to your phone is those are subscribed).
Let's implement the above setup using AWS. You need to have an account to follow the demo presented in this article. Though, there some notes you need to remember while using your AWS account :
- Never work directly with the root account (as it has all privileges eve, access to billing information).
- Create a IAM user, save it's ACCESS and SECRET keys and grant it SNS and SQS accesses.
After successful login to your account, you would see the following console shown below :

AWS classifies services into categories which makes it easy to navigate through them (one can use the search bar to access a specific service quickly).
Setting up AMAZON SNS
- Type in the search bar "SNS" as shown below :

- AWS prompts you to write down a topic name :then click on "next step".

- AWS asks for an optional detail which is displayed as a subject in case of sending an email or an SMS :Let's keep the configuration simple. Then click "Create topic" in the bottom page.

- Check your settings in the resume page :
Congratulation, Your SNS topic is up and running (The ARN in the picture above identifies your topic, we're going to need it for publication).





Setting up Amazon SQS
- Browse to SQS (just use the search bar as we did previously with SNS),

- Enter a queue name, and choose a queue type (Standard or FIFO); We're going to choose Standard in this example as shown below :
then click on quick queue creation (we're going to dive into more details in the next articles).

- Check your queue settings in the summary page :

- Subscribe the queue to SNS service :
- Right click on the freshly created queue as shown below :
 and choose the option "Subscribe to SNS topic".
and choose the option "Subscribe to SNS topic".
- You only need to select to corresponding SNS topic to which you need to subscribe :
 then click on "subscribe".
then click on "subscribe". - At this step, the SQS queue is subscribed and will receive all messages that are sent to your SNS topic (see confirmation page below).

- Right click on the freshly created queue as shown below :
- Add your email address as a subscriber (optional) :
- Browse to SNS, and select your topic. Scroll down and click on the button "add subscriber" as shown below :

- Fill the form with your corresponding email address as illustrated below :
A confirmation email will be sent to your email account (just click on the confirmation link). Now, every time a message is received by SNS; it will be dispatched to both SQS and your email address.

- Browse to SNS, and select your topic. Scroll down and click on the button "add subscriber" as shown below :








Test a design using AWS tools
AWS ships with multiple tools to test different services and check the correctness of interactions between them.As a Rule of thumb, always check your work using AWS tools before writing any code on your side (this can save hours of debugging).
We're going to take a look to a ready to use tool able to send messages to our SNS topic.
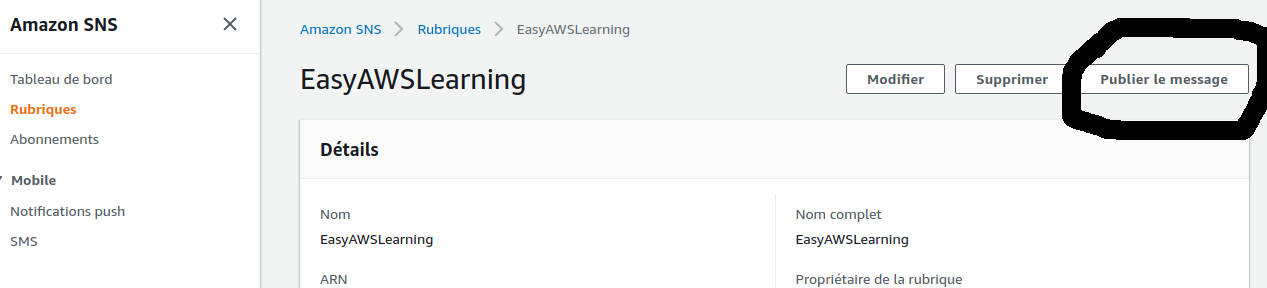
- Navigate to your SNS topic as shown below :
and click on "publish message" button (which allows to send a message to your topic).

- An empty message template would appear :
- Fill the object field :

- Write your message in the body block :
 Then click on "Publish Message" in the bottom of the page.
Then click on "Publish Message" in the bottom of the page.
- Fill the object field :
- Check message delivery :
- Browse to your SQS queue and observe that the number of messages has changed :
 You can click on it and read it's content.
You can click on it and read it's content.
- If you have registered your email to SNS in the last step, you should receive an email as well :

- Browse to your SQS queue and observe that the number of messages has changed :




Now, our system is working properly; let's have some python code to read the content of our SQS queue.
Simple publisher
As mentioned previously, AWS provides various SDKs to interact with it, here is an example of using python and the famous boto3 SDK.Publishing a message to SNS is simple as shown below :
import boto3 # Create an SNS client client = boto3.client( "sns", # Choose SNS service aws_access_key_id="YOUR_ACCESS_KEY", # equivalent to username aws_secret_access_key="YOU_SECRET_KEY", # equivalent to password region_name="us-east-1" ) # Send your sms message. client.publish( TopicArn='arn:aws:sns:us-east-1:YOUR_ACCOUNT_NUMBER:EasyAWSLearning', Subject='ALERT MESSAGE AWS', Message="Hello World from AWS!" )

And because I have registered my email address to SNS, the message will be relayed to my account :

Conclusion
Any organization can delegate the bulky work of maintaining, storing and processing millions of data to AWS. the latter ensures high availability, reliability and security. With more than 195 services, it became the de-facto choice when building scalable and resilient applications. Netflix has even moved a big portion of it's streaming operations into AWS.Today, we have made a first step into Amazon SNS and SQS in order to give the reader more insight into the world of Amazon services.
More articles will be available soon with more details. Have fun!



























